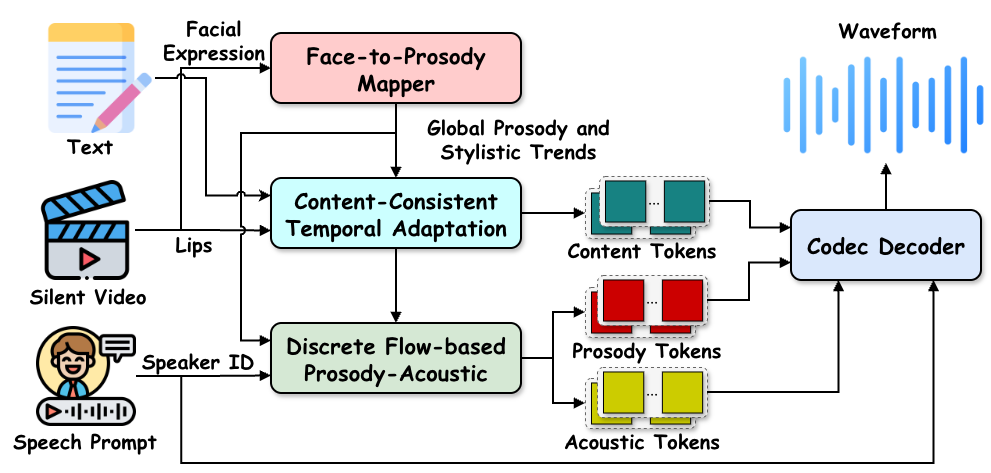
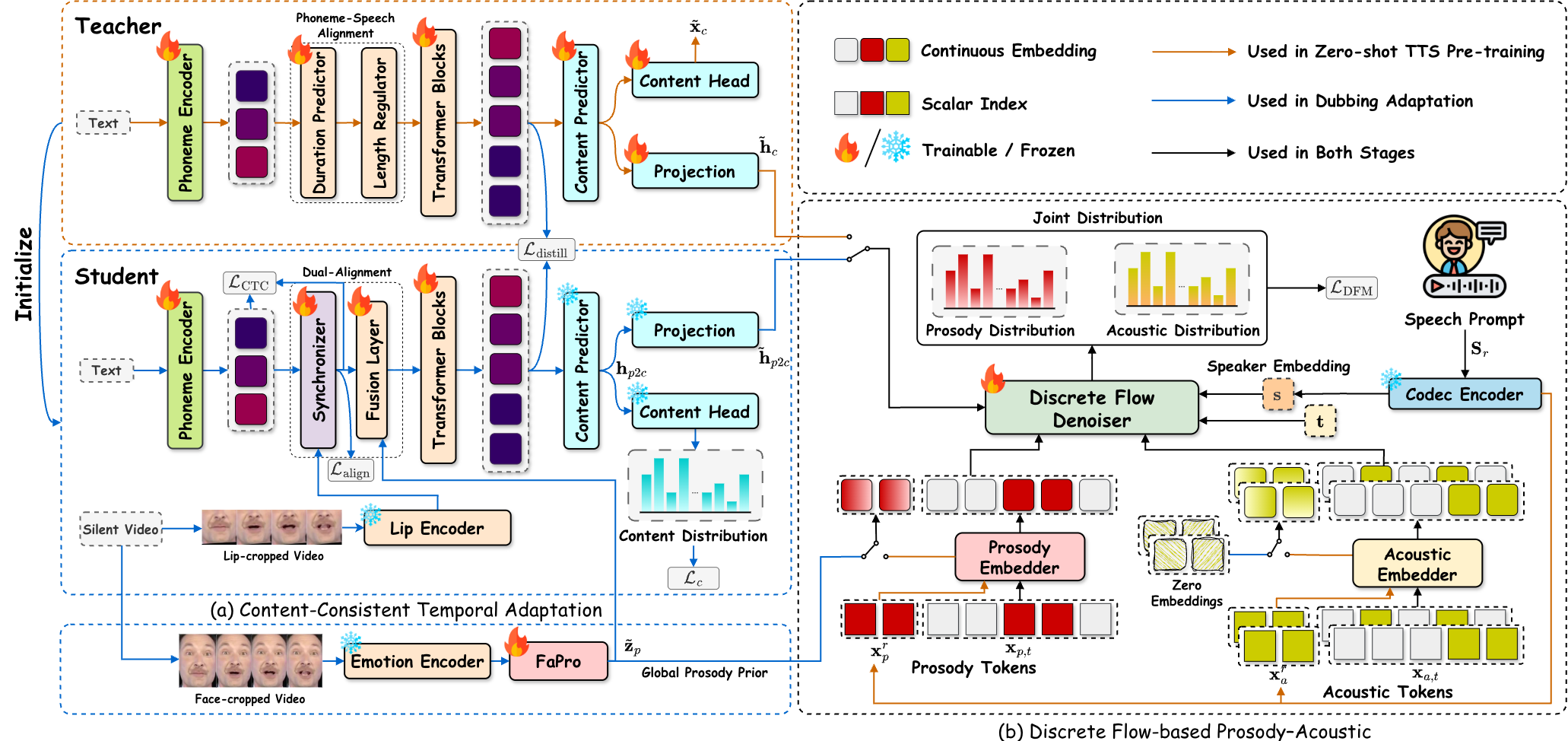
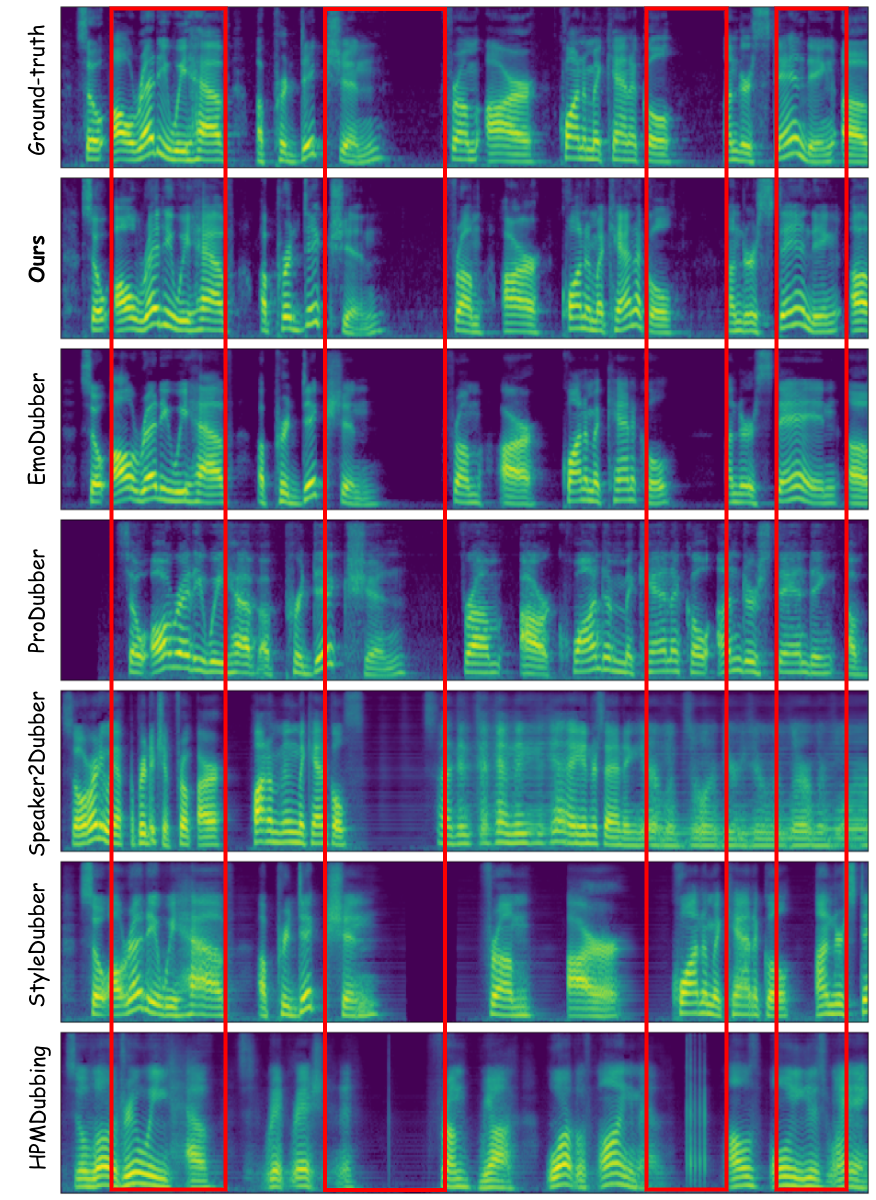
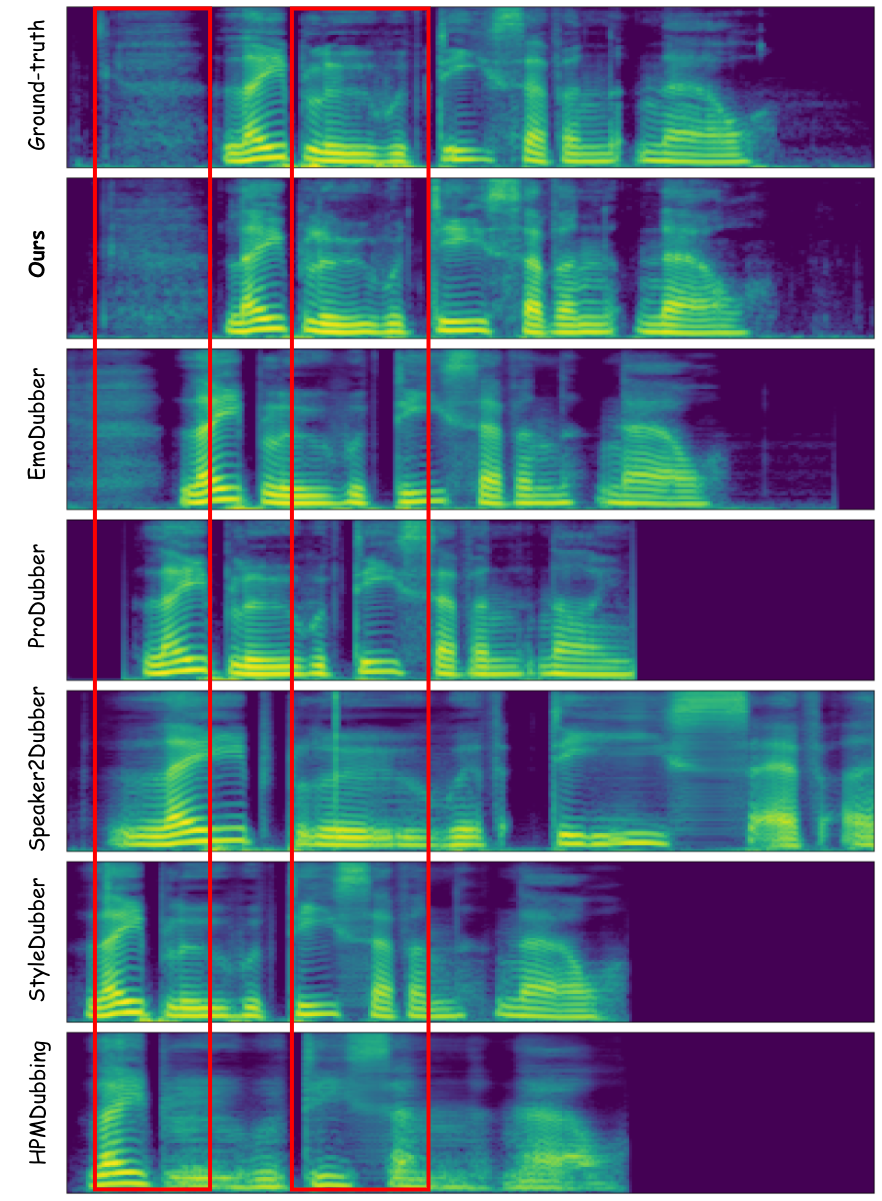
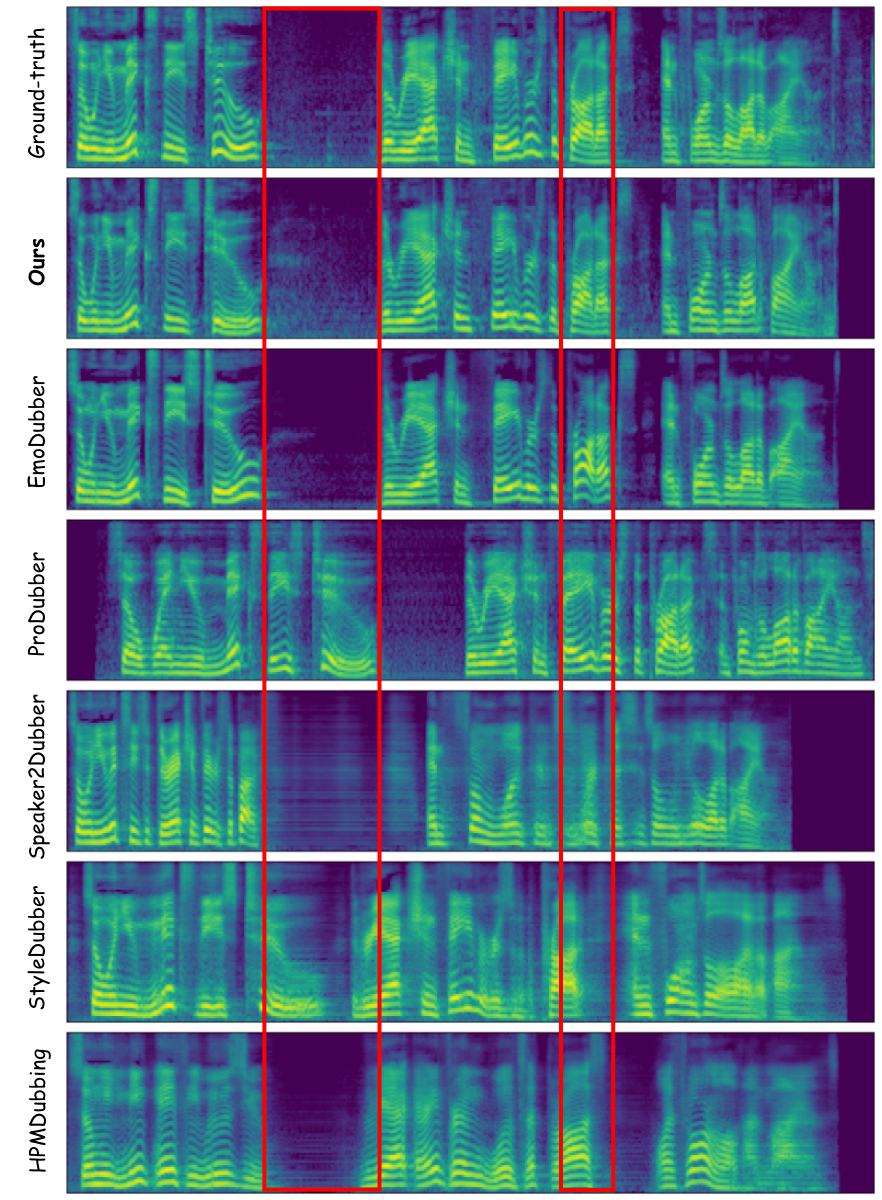
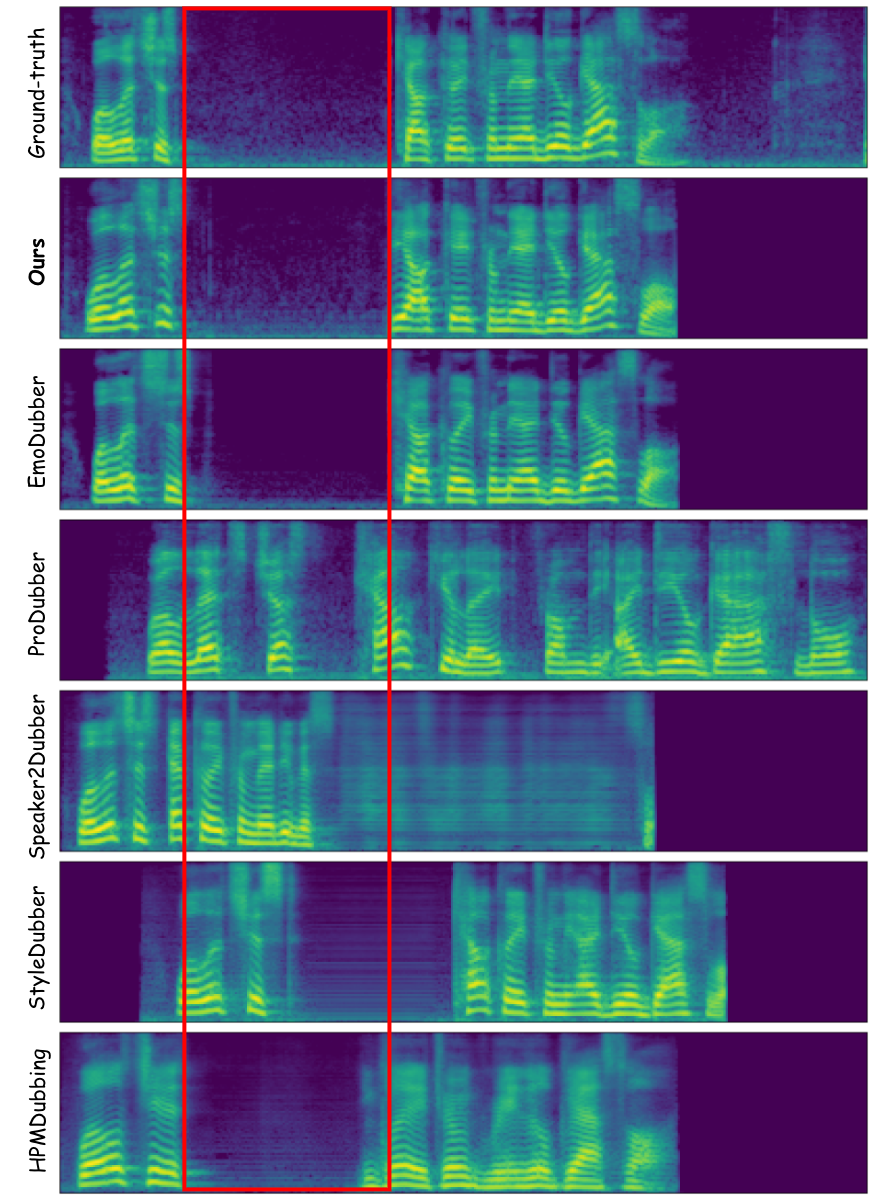
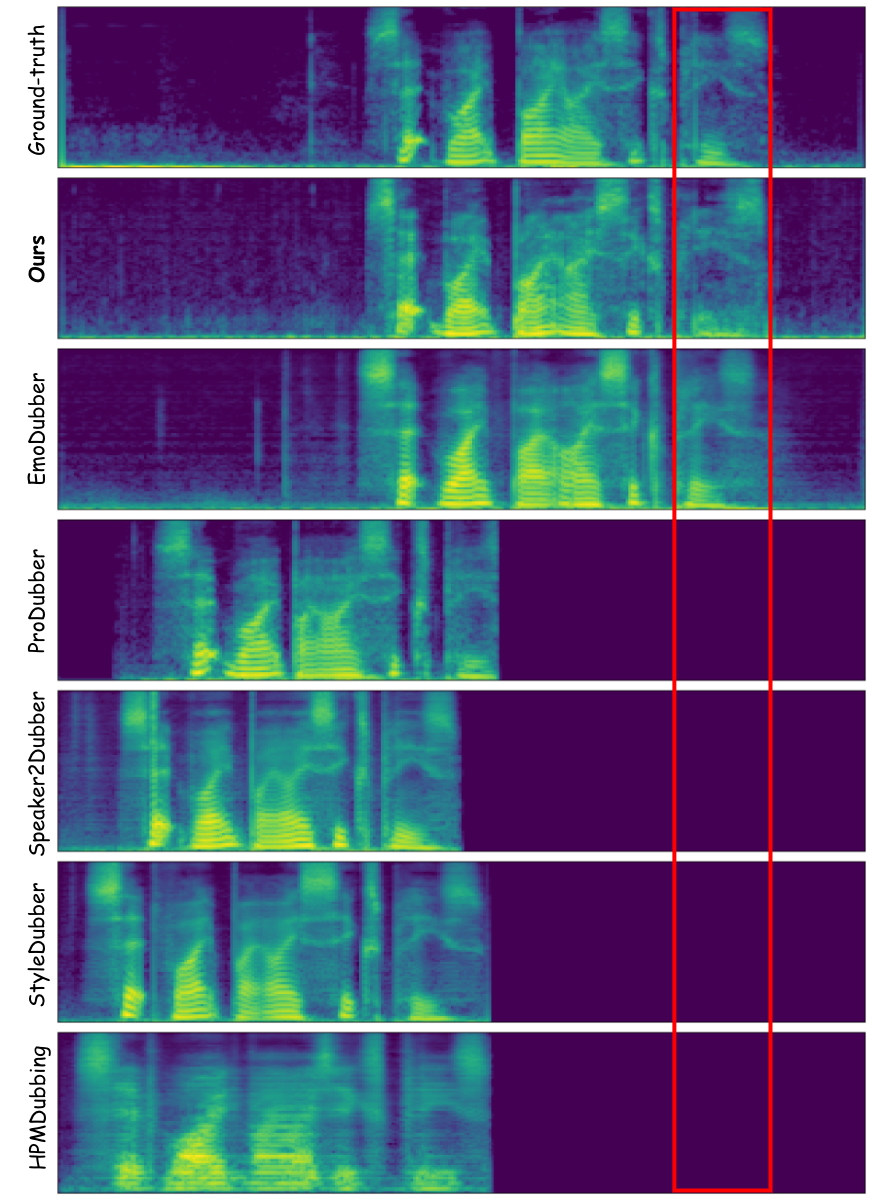
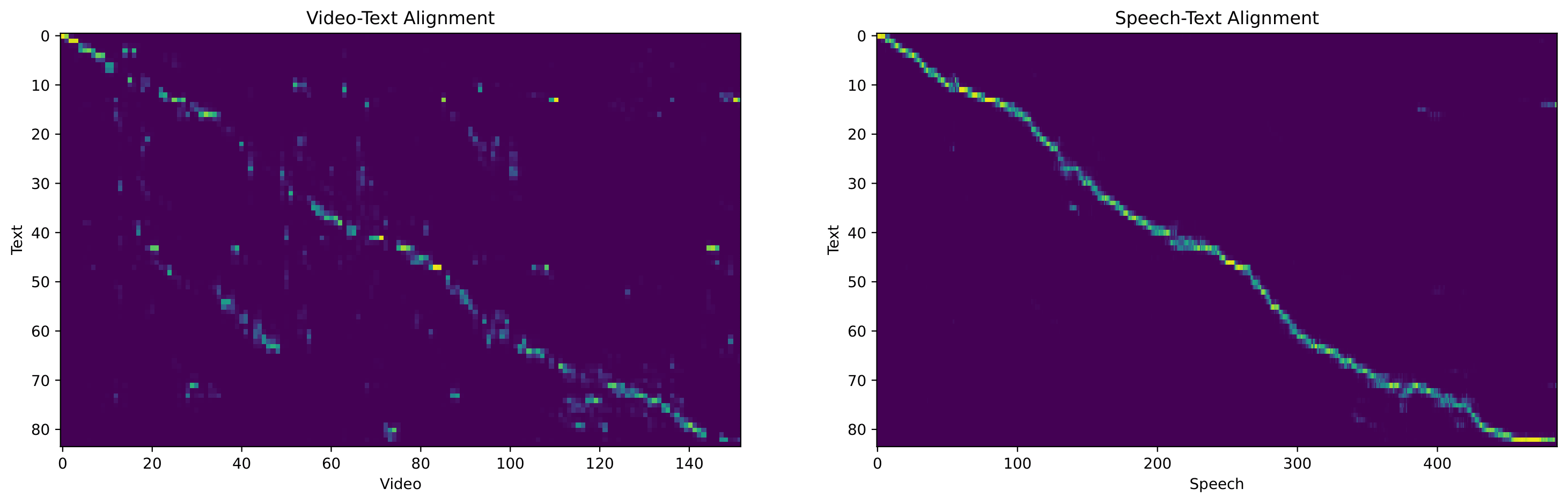
Video dubbing requires content accuracy, expressive prosody, high-quality acoustics, and precise lip synchronization, yet existing approaches struggle on all four fronts. To address these issues, we propose DiFlowDubber, the first video dubbing framework built upon a discrete flow matching backbone with a novel two-stage training strategy. In the first stage, a zero-shot text-to-speech (TTS) system is pre-trained on large-scale corpora, where a deterministic architecture captures linguistic structures, and the Discrete Flow-based Prosody-Acoustic (DFPA) module models expressive prosody and realistic acoustic characteristics. In the second stage, we propose the Content-Consistent Temporal Adaptation (CCTA) to transfer TTS knowledge to the dubbing domain: its Synchronizer enforces cross-modal alignment for lip-synchronized speech. Complementarily, the Face-to-Prosody Mapper (FaPro) conditions prosody on facial expressions, whose outputs are then fused with those of the Synchronizer to construct rich, fine-grained multimodal embeddings that capture prosody-content correlations, guiding the DFPA to generate expressive prosody and acoustic tokens for content-consistent speech. Experiments on two benchmark datasets demonstrate that DiFlowDubber outperforms prior methods across multiple evaluation metrics.

 2.
2.  3.
3.